Volver a proyectosCaso destacado
Transcriber
Flujo de transcripción de escritorio que convierte URLs compatibles en transcripciones estructuradas sin depender de varias herramientas de terminal.
Contexto
Se diseñó a partir de un flujo repetido: descargar medios, elegir el backend de transcripción correcto y formatear una salida limpia suele requerir varias herramientas separadas.
Problema
Transcribir audio de cualquier URL soportada por yt-dlp (incluyendo videos y playlists de YouTube) exigía aprender flags de yt-dlp/ffmpeg y coordinar varias herramientas para escoger backend y formatear la salida.
Solución
Transcriber unifica yt-dlp, Whisper y FFmpeg en un flujo PyQt6 donde el usuario puede elegir modelo, backend, idioma y preferencias de salida sin salir de la aplicación.
Decisiones clave
- -Se expuso la elección del backend para adaptarse a CUDA, DirectML o CPU según la máquina disponible.
- -Se mantuvieron logs visibles y rutas configurables porque estos flujos fallan de formas reales que el usuario necesita inspeccionar.
- -Se exportó en Markdown con metadatos para que la salida sea útil más allá del texto crudo.
Capturas
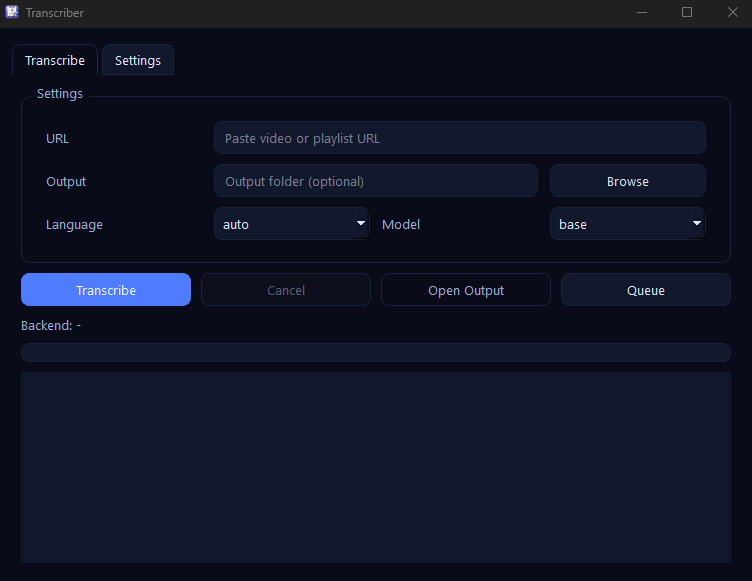
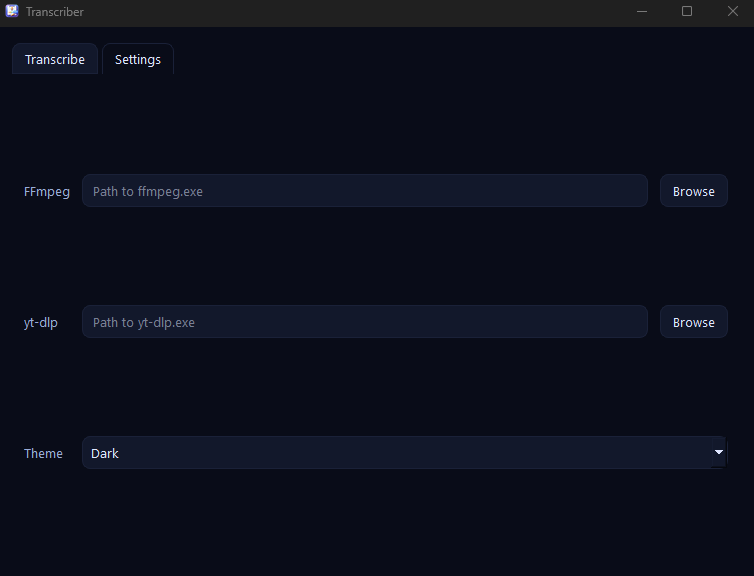
Características clave
- -Descarga audio de videos individuales o playlists completas con yt-dlp
- -Elige el modelo Whisper (tiny/base/small/medium) con idioma fijo o detección automática
- -Selecciona backend CUDA, DirectML o CPU y mantiene visibles los logs del proceso
- -Configura rutas de ffmpeg/yt-dlp, carpeta de salida y tema (sistema/claro/oscuro)
- -Exporta transcripciones en Markdown con metadatos del video
Resultados
- -Convirtió un flujo técnico y fragmentado en una experiencia de escritorio unificada.
- -Muestra mejor criterio de producto alrededor de tooling con IA, configuración y calidad de salida.
- -Aporta al portafolio una pieza con valor claro para creadores, investigadores o usuarios que trabajan con audio largo.
Stack
PythonPyQt6OpenAI Whisperyt-dlpFFmpegPyTorch